Towards PyTorch-Native Auto-Parallel Framework
Abstract
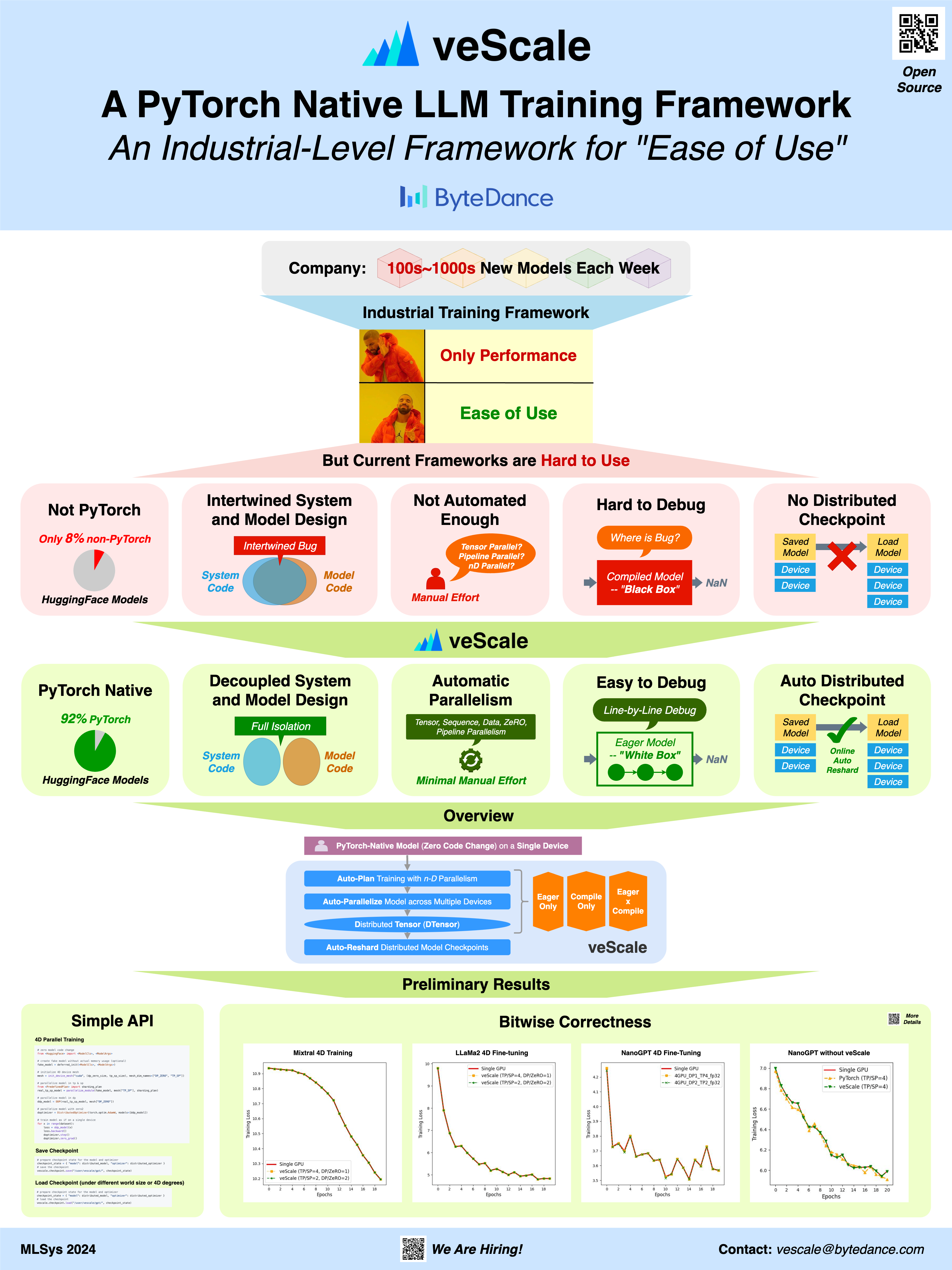
Introduction. The era of giant model today calls forth distributed training. Despite countless distributed training frameworks have been published in the past decade (e.g., FlexFlow, Alpa, to name a few), few have excelled at the Ease of Use and development extensibility demanded by the real industry production, as the quality most favored for a framework is often the Ease of Use instead of pure Performance. Companies developing 100s~1000s models a week benefit the most from a framework that is both easy to use and extend, and provides elegant encapsulation of models, configurations and infrastructure APIs. The Ease of Use of a framework for training and developing LLM lies in two essentials -- PyTorch and Automatic Parallelism, because: i) PyTorch ecosystem dominates the ML community today and owns 92% models on HuggingFace and 70% research on Papers with Code, and ii) gigantic models with 100s billions parameters cannot be trained without 3D Parallelism where manually distributing or tuning each operator or layer takes forever. (By Automatic Parallelism, we meant both automatic model distribution across devices and automatic parallelism strategy search.)
Problem. Currently, this Ease of Use is "broken" for industry-level frameworks, as they are either not PyTorch-native or not fully Automated in parallelism. The famous frameworks can be categorized as below:
- Not PyTorch-native: TensorFlow, JAX, and Ray alienate themselves from the majority of ML community.
- Neither PyTorch-native nor Automated: Megatron-LM is essentially not a framework but a system specialized for Transformers, with: i) customized operators and runtime, preventing its easy extensibility like native PyTorch, and ii) intertwined system design with model architecture, which requires system experts to not only manually rewrite the model for distributed training with a tons of care, but also painfully debug within the deeply coupled system and model code.
- Neither PyTorch-native nor Fully Automated: DeepSpeed also relies on customized operators of Transformers and runtime engine. While it allows automation to some extent (e.g., auto-TP), however, it still misses the unified automation in 3D parallelism, let alone the optimal parallelism strategy.
- Not Fully Automated: PyTorchDistributed family (FSDP, PiPPy, TP, and DDP) is indeed PyTorch-native. However, it still requires manual configuration and tuning. Furthermore, each of those family members was developed in isolation without a holistic design perspective, preventing an unified 3D automation.
Approach.
To this end, we take an initial step to fix the "broken" by proposing a novel industry-level framework that, for the first time, combines PyTorch Nativeness and Automatic Parallelism for scaling LLM training with the Ease of Use.
Ideally, we only expect model developers to write "Single-Device" model code with native torch.nn.Module and then we automatically parallelize it across many devices in a "6D" parallelism search space with all the optimizations and heavy lifting handled transparently.
However, two major challenges exist: i) PyTorch is not designed for distributed programming and lacks a mature abstraction for "Single-Program-Multiple-Data (SPMD)", and ii) PyTorch is "Eager-First" framework that models are always written in Eager mode, leading to capturing of model graph notoriously hard (e.g., dynamic control flows, custom hooks, callbacks, flattened parameters, debuggers, etc.). No model graph means no automatic parallelism for existing frameworks and publications, as all rely on a "perfect model graph" to begin with.
In our framework, we enable the SPMD paradigm from PyTorch internals by extending and enhancing an experimental primitive, PyTorch DTensor, to provide a global tensor semantic with local shards distributed on multiple devices. On top of our DTensor, we developed the prototype of 6D parallelism (Tensor/Sequence/Expert/Data/ZeRO/Pipeline Parallelisms) with a unified configuration and API. Furthermore, we are inventing an Eager-Mode Planner that can automatically generate the best 6D configuration WITHOUT relying on model graphs at all. Meanwhile, our Planner can also be mixed with Compiler mode. Our preliminary results show that the top-3 models on HuggingFace, without code changes, can be automatically parallelized using our framework for distributed training on multiple devices while matching the loss curve of a single-device training.
Our framework is now open-source for the MLSys community.
Poster