veScale: A PyTorch Native LLM Training Framework
TLDR
An Industrial-Level Framework for Ease of Use:
(* is under development.)
Why veScale
The era of giant models today calls forth distributed training. Despite countless distributed training frameworks that have been published in the past decade (to name a few), few have excelled at the Ease of Use and development extensibility demanded by real industry production, as the quality most favored for a framework is often the Ease of Use instead of pure Performance. Companies developing 100s~1000s models a week benefit the most from a framework that is both easy to use and extend, and provides elegant encapsulation of models and clean APIs.
The Ease of Use of a framework for training and developing LLM lies in the following essentials:
-
🔥 PyTorch Native: PyTorch ecosystem dominates the ML world and owns 92% of models on HuggingFace and 70% of research on Papers with Code; Alienating from PyTorch ecosystem makes a framework hard to adapt and extend.
-
🛡 Zero Model Code Change: Users' model code should remain untouched, instead of being intertwined with framework code, which requires users to not only manually rewrite the model for distributed training with tons of care, but also painfully debug within the deep coupled model and framework code.
-
🚀 Single Device Abstraction: Model developers should focus on developing model architecture itself with single device semantics, rather than being distracted by the complex and error-prone management of multiple devices and diverse interconnects in distributed environments.
-
🎯 Automatic Parallelism Planning: Gigantic models cannot be trained without nD Parallelism (Tensor, Sequence, Data, ZeRO, Pipeline Parallelism, etc.). Users' giant models should be automatically scaled by a framework for nD parallel training, instead of being manually planned and tuned for each operator or layer under different cluster settings, which takes forever.
-
⚡ Eager & Compile Mode: Users should enjoy both Eager and Compile mode offered by a framework with:
- Eager mode for fast development, convenient debugging, and customization with callbacks and control flows;
- Compile mode for ultimate performance boost with a single click.
-
📀 Automatic Checkpoint Resharding: Training models and optimizer states should be saved/loaded automatically and performantly in distributed settings, and can even be online resharded across different cluster sizes and different nD Parallelism.
What is veScale
veScale's overview is as follows:
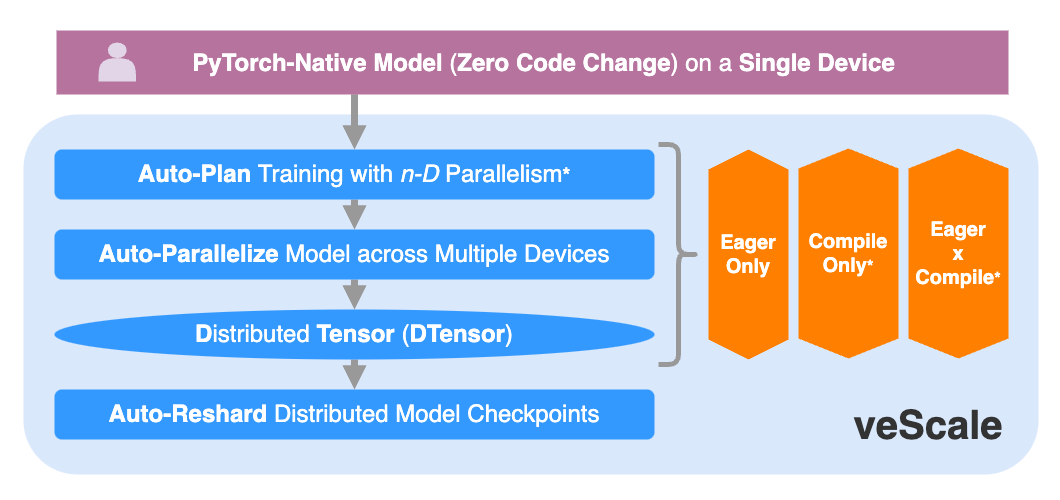
We take an initial step to develop an Industry-Level framework, veScale, that focuses Ease of Use for scaling LLM training, by combining PyTorch Nativeness and Automatic Parallelism*.
Ideally, veScale only expects model developers to write a simple model code with native torch.nn.Module under Zero Code Change as if running on a Single Device, and then veScale will automatically parallelize it across a cluster of devices in a nD Parallelism search space with all the optimizations and heavy lifting handled transparently.
Unlike existing frameworks that rely on Compile mode and a "perfect model graph" for Automatic Parallelism, veScale is inventing an Eager-Mode-ONLY* Automatic Parallelism that does not rely on the model graph at all. Furthermore, veScale is also developing a Mixed Mode* of partial Eager and partial Compile.
veScale is designed and implemented on top of a primitive called DTensor that provides a global tensor semantic with local shards distributed on multiple devices. veScale extends and enhances the PyTorch DTensor for our production standard, and further develops the Auto-Plan* and Auto-Paralleize with a unified configuration and API.
Furthermore, veScale also supports online Auto-Reshard for distributed checkpoints.
(* is under development)
Status of veScale
veScale is still in its early phase.
The tentative open-source timeline can be found in the veScale repo.