内容识别
内容识别 Agent (Interest Agent) 通过自然语言处理技术和正则表达式匹配,自动识别群聊中的目标信息,感知潜在问题并进行告警提示。该智能体可以帮助团队及时发现群聊中提及的重要信息,如严重故障、客情风险、异常行为等。
设计模式
内容检测配置
不同检测目标对象/规则(Interest)互相解耦,可保证在在修改或删除某个规则时,不影响其他规则的正常运行,满足多样化的业务需求,减少维护成本。
Interest Agent 初始化
内容识别 Agent 支持两种检测模式,可根据场景灵活选择:
- 语义检测(Semantic)
- 基于大语言模型的语义理解进行智能识别
- 支持自定义识别条件的自然语言描述
- 通过正例/负例学习(Few-shot Learning)提高识别准确率
- 正则表达式检测(Regex)
- 基于正则表达式进行精确匹配
- 适用于结构化内容和明确模式的识别
- 执行效率高,适合快速且严格匹配筛选场景
检测执行
通过 ParallelAgent{: target="_blank" rel="noopener noreferrer"} 支持并行执行多个检测任务,不会因规则数量增加而影响检测效率。
告警生成与过滤
为减少误报和告警疲劳,支持不同方法的告警过滤机制:
- 语义过滤:基于语义检测方法,可以在检测到特定目标时拦截告警
- 例:关注
大范围问题,但同时设置测试环境为抑制策略,当消息中提及测试环境的大范围问题时,则不会发送该告警
- 例:关注
- 告警抑制:设置告警间隔,避免同一群聊短时间内重复告警
- 告警优先级:支持自定义对不同订阅内容设置不同优先级,便于区分处理
配置与概念说明
每个检测目标对象 Interest 包含以下基本概念:
| 字段 | Field | Prompt注入 | 说明 | 示例 |
|---|---|---|---|---|
| 名称 | name | 否 | 识别规则名称 | "生产环境服务故障" |
| 描述 | description | 是 | 识别条件的自然语言描述 | "识别生产环境的严重服务故障" |
| 正例 | examples_positive | 是 | 应该被识别的消息示例(支持多个) | ["生产API服务挂了", "数据库响应超时"] |
| 负例 | examples_negative | 是 | 不应该被识别的消息示例(支持多个) | ["开发环境测试失败", "性能还有优化空间"] |
| 检测类型 | action_category | 否 | Detect(满足条件则产生告警) Filter(满足条件则抑制告警) | "Detect" |
| 判别类型 | inspect_category | 否 | Semantic(语义识别) RE(正则匹配) | "Semantic" |
| 正则表达式 | regular_expression | 否 | 正则表达式(当检测类型为RE时必填) | SVIP|VIP |
| 历史消息数 | inspect_history | 否 | 需要分析的消息窗口(>=0, 0表示所有消息) | 10 |
| 告警抑制间隔 | suppress_interval | 否 | 同一群聊内告警抑制间隔(默认6小时) | 6 |
| 事件级别 | event_level | 否 | P0、P1、P2、None | "P1" |
场景示例
语义检测场景示例
描述:识别生产环境的严重服务故障,包括服务不可用、大量错误、严重性能下降
正例:
- "生产API服务挂了,大量502错误"
- "数据库响应时间从100ms激增到10秒"
- "订单服务完全不可用,错误率100%"
负例:
- "开发环境测试出现了一些错误"
- "昨天修复的小bug"
- "性能还有优化空间"
历史消息数:1
告警抑制间隔:6小时
::
描述:识别客户投诉、强烈不满或可能的客情风险
正例:
- "大客户说要退款,非常不满"
- "客户投诉功能完全不能用"
- "用户在社交媒体上公开抱怨"
负例:
- "客户来问这个的使用方法"
- "用户说这里有个小问题"
- "客户反馈这里优化一下"
历史消息数:5
告警抑制间隔:6小时
正则表达式检测场景示例
描述:识别可能的危险数据库操作
匹配模式:(DROP\s+TABLE|TRUNCATE|DELETE.*FROM.*WHERE\s+1=1)
历史消息数:1
告警抑制间隔:1小时
::
描述:识别包含SVIP或VIP关键词的消息,SVIP发起的任意请求
匹配模式:SVIP|VIP
历史消息数:1
告警抑制间隔:6小时
描述:识别包含告警关键词的消息
匹配模式:(\[ALERT\]|\[CRITICAL\]|告警|紧急)
历史消息数:1
告警抑制间隔:1小时
::
效果展示
| 问题处理群 | 告警监听群 |
|---|---|
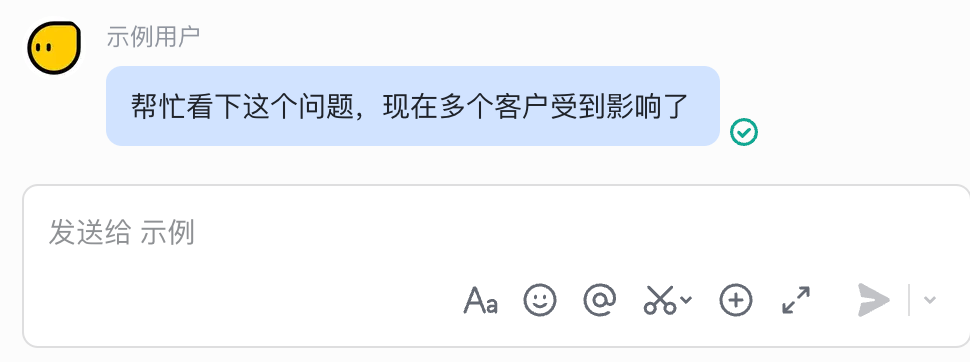 | 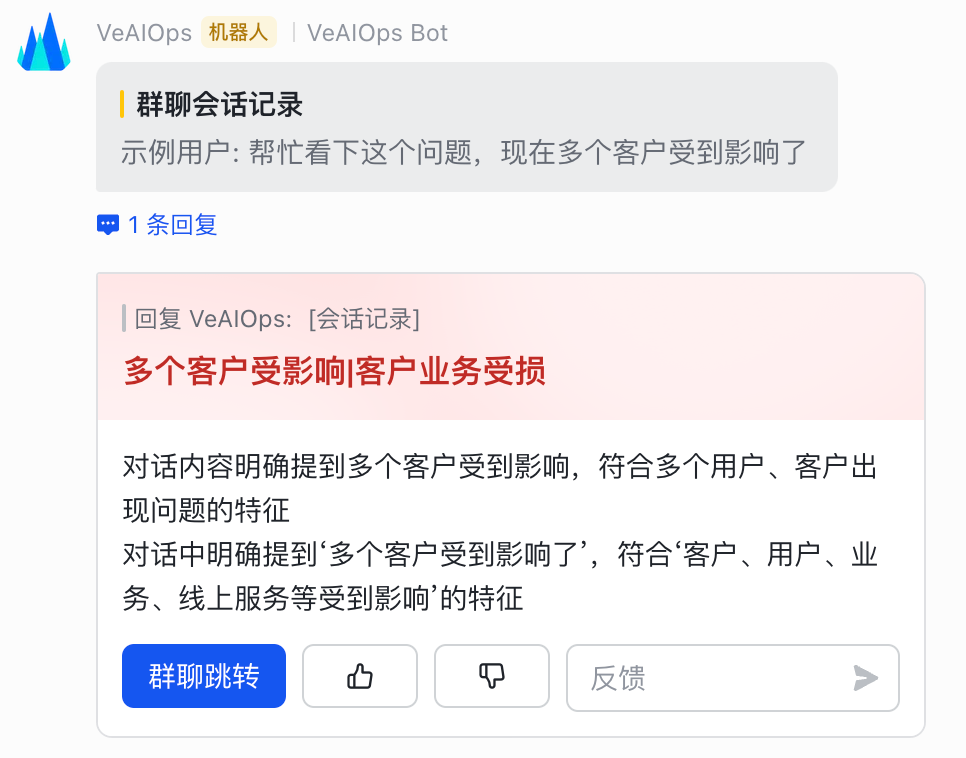 |
实践与优化建议
检测结果与实际模型效果有关,合理配置和优化可以提升检测效果与实用性,这里分享常用优化思路。
语义检测 vs 正则表达式检测,尽管语义检测更具灵活性和智能化,但正则表达式仍具有高效与结构化的优势。
- 使用语义检测的场景:
- 需要理解上下文和语义的复杂场景
- 表达方式多样、难以用规则描述的情况
- 示例:客情识别、问题严重性判断
- 使用正则检测的场景:
- 结构化明确的内容匹配
- 需要快速处理大量消息
- 示例:客户ID识别、SVIP/VIP识别、数据库危险操作(DROP)识别 ::
对于会被注入到大语言模型 Prompt 中的描述、正例和负例,高质量的编写能显著提升识别效果。
- 描述要点:
- 具体明确,突出关键特征,避免模糊不清
- 设计判断标准和边界条件
- 在描述中强调匹配严格成度,例如
明确提到如下特征等
- Few-shot Learning:
- 可使用
正例与负例的形式,提供若干个典型场景 - 考虑不同的表达方式
- 区分容易混淆的边界情况
- 可使用
- 从检测结果中调整:
- 定期评估检测效果
- 根据误报和漏报情况,调整描述和示例(或使用AutoPrompt相关技术自动优化) ::
合理配置告警过滤和抑制策略,能有效减少误报和告警疲劳。
- 告警过滤:
- 告警过滤是内容检测的另一种使用方式,用于匹配那些我们不希望收到告警的消息
- 同样支持
语义检测和正则检测两种模式 - 示例:过滤已处理、非紧急或测试环境相关的消息 告警抑制:
- 一事一群:通常不同事件使用不同群聊处理,多通过告警过滤策略,告警抑制(设置为较大数值)即可
- 示例:Oncall群聊
- 多事一群:同一群聊内处理多个事件时,建议设置合理的告警抑制间隔,允许多次告警,但避免重复告警
- 示例:客户服务群聊 ::
并非所有消息内容都需要每次被分析检测
- 检测窗口与群聊消息发送习惯和实际处理状态有关,建议根据实际情况进行调整。
- 过多的历史消息会增加处理时间和 API 成本,应根据实际需求权衡。
- 过多的历史消息会触发更多的误报。 :: ::