veScale Distributed Data Parallel (DDP)
TLDR
What is DDP?
Distributed Data Parallel (DDP) is the most used parallelism strategy for distributed training. It partitions the input data batch across multiple devices, replicates the model on each device, and synchronizes gradient (e.g. with AllReduce) in the background.
veScale DDP is primarily inherited from Megatron-LM's DDP for its performance and compatibility with ZeRO optimizer. We extend and enhance the original DDP with extra features surrounding veScale DTensor and DModule:
-
conversion between
DTensorandTensorgradients -
support nested gradient synchronization with
DModule(for Sequence Parallel) -
support gradient synchronization for dynamic control flow
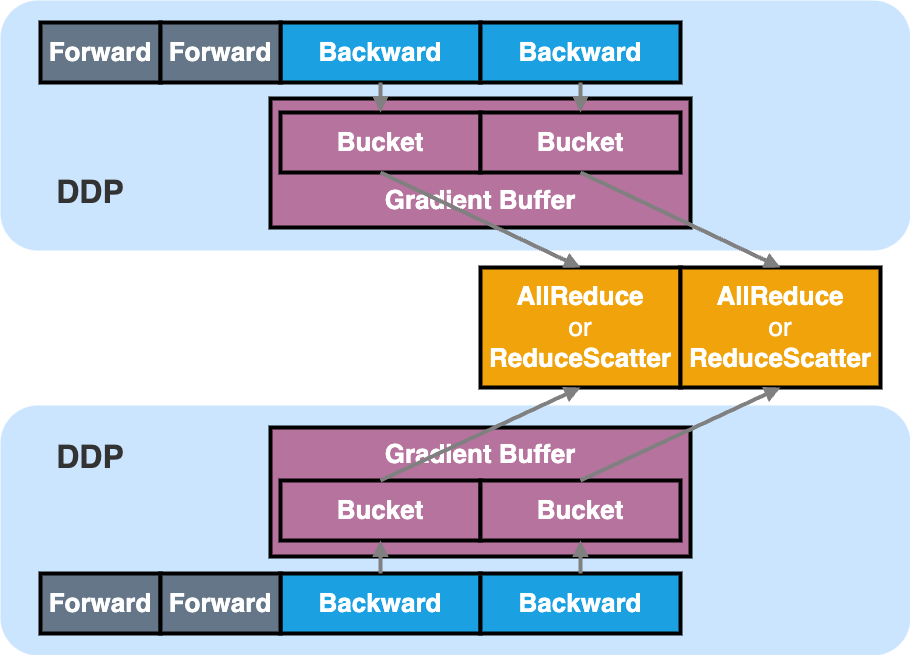
How does DDP work?
DDP is a module (DModule) wrapper that creates a flattened Gradient Buffer that stores the gradients produced by the model backward.
(This is achieved by adding a hook to the grad_fn of the model parameters, which fills DTensor gradient outputed by PyTorch Autograd engine to the pre-allocated grad buffer.)
The purpose of Gradient Buffer is to both accelerate gradient synchronization and reduce memory fragmentation, as it only needs to be performed once for the entire buffer, rather than once per parameter.
For extreme performance, the Gradient Buffer is further divided into multiple _Bucket_s such that the backward compute and gradient synchronization of each Bucket can be overlapped. As soon as all gradients in a Bucket are generated, we can immediately trigger the gradient synchronization rather than waiting until the whole Gradient Buffer is ready.
The gradient synchronization can be either AllReduce or ReduceScatter under the DDP hood:
-
AllReduceis used when no ZeRO optimizer -
ReduceScatteris used when ZeRO optimizer (e.g.,DistributedOptimizer) exists
How to use DDP?
-
APIs can be found in
<repo>/vescale/ddp/distributed_data_parallel.py -
More examples can be found in
<repo>/test/parallel/ddp_optim/test_ddp.py