VeDeviceMesh for nD Parallelism
TLDR
(* is under development.)
What is VeDeviceMesh?
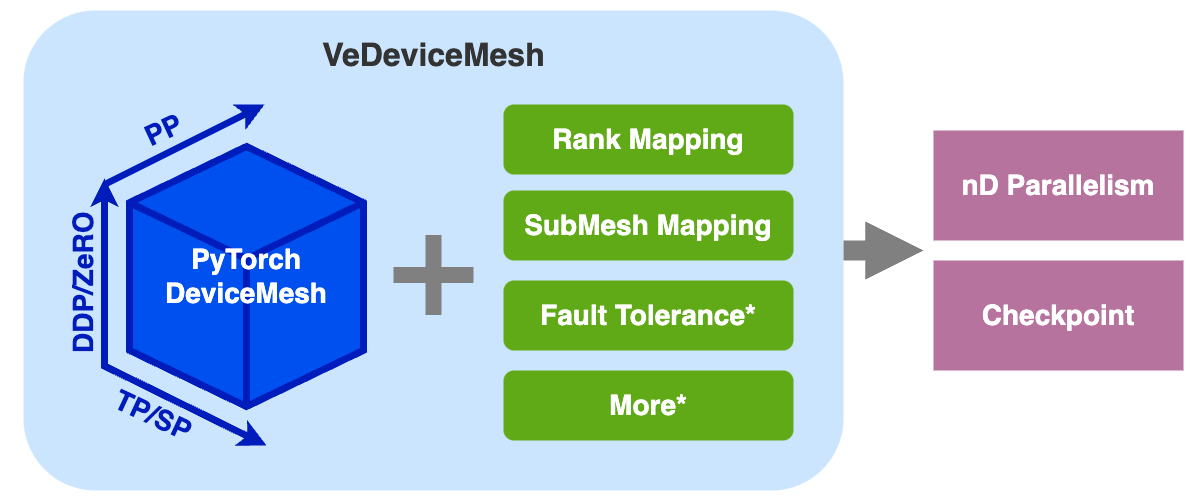
VeDeviceMesh (veScale Device Mesh) is an advanced API that is built on top of PyTorch native's DeviceMesh. This API enhances the existing capabilities of DeviceMesh, enabling effective nD parallelism strategies, checkpointing, and easy-to-use APIs, with ideals below:
-
“A DeviceMesh, but better”
-
One “Mesh” fits all: users don't need to worry about meddling with DeviceMesh and ProcessGroups' throughout the course of training. Additionally, users make the most out of the same DeviceMesh to enable hybrid parallelization training.
-
Easy to extend: for more refined capabilities for imminent parallelization methods in the future,
VeDeviceMeshprovides mature APIs to extend new functionalities without breaking the semantics of communication
How does VeDeviceMesh work?
VeDeviceMesh wraps around PyTorch DeviceMesh with APIs that seamlessly integrate with APIs of veScale's DModule, DDP, DistributedOptimizer, Pipeline Parallel, and Checkpoint.
VeDeviceMesh further implements advanced features surrounding DeviceMesh:
-
rank mapping between local rank and global rank or between strategy coordinates and global rank
-
submesh mapping between global mesh and submeshes or between local submesh and neighbor submeshes
-
[in future] fault tolerance with reconfigurable meshes
How to use VeDeviceMesh?
-
APIs can be found in
<repo>/vescale/devicemesh_api/api.py -
More examples can be found under
<repo>/test/parallel/devicemesh_api/*.py