veScale Optimizer Parallel
TLDR
Overview
In veScale, we provide two optimizers for Optimizer Parallel:
-
DistributedOptimizer -
BasicOptimizer
veScaleDistributedOptimizer
What is it?
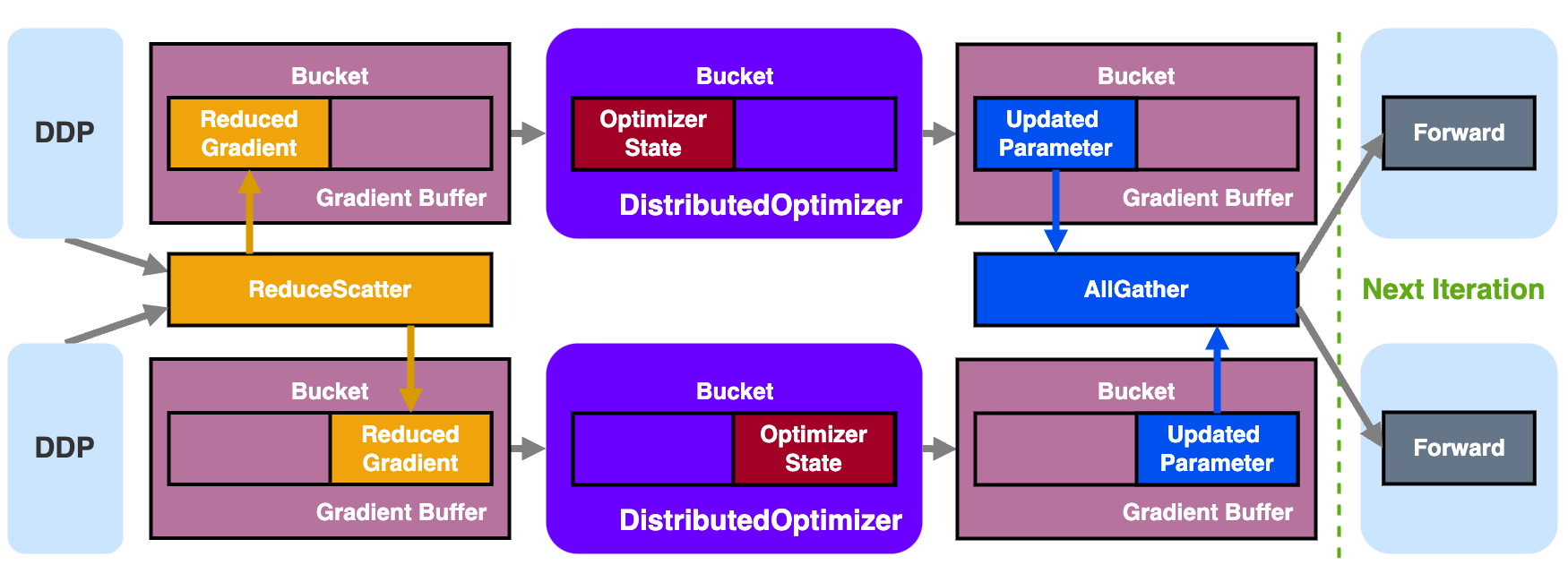
DistributedOptimizer is a ZeRO 2+ optimizer. Similar to the original ZeRO2, it parallelizes model gradient and optimizer states along Data Parallel dimension. Differently, it further parallelizes model parameters virtually but not physically.
DistributedOptimizer is primarily inherited from Megatron-LM's DistributedOptimizer for its performance and mostly due to the lacking of ZeRO2 optimizer in native PyTorch. We extend and enhance DistributedOptimizer with extra features:
-
convert between
TensorandDTensor -
support online resharding of optimzier state
How does it work?
In DistributedOptimizer, the model gradients and optimizer states are sharded along Data Parallel dimension in each gradient Bucket of Gradient Buffer (see DDP for more details), where each DP rank only manages its own shard of gradient, generates its own shard of optimizer states, and updates its own shard of parameters.
The flow of DistributedOptimizer is as follows:
- During initialization, model parameters are virtually sharded across all DP ranks, such that each DP rank owns a partial view of the original model parameters
- This sharding does not respect parameter boundaries, i.e., a parameter could be split into two halves and belong to two DP ranks. Therefore, a complex mapping between the sharded parameters and the original parameters is established, which is mostly done in the
__init__function. Then the optimizer'sparam_groupsis replaced with the Sharded Parameter.
-
Receive Reduced Gradient resulting from
ReduceScatterper Gradient Bucket inDDP -
Attach Reduced Gradient (
main_gradof each original parameter) to the Sharded Parameter -
Run the actual
optimizer.step()to generate Optimizer State of each shard and updates Sharded Parameter with Reduced Gradient -
Copy the updated Sharded Parameter to a specific parameter buffer and get ready for
AllGathercommunication to restore the full parameters
- To avoid the performance overhead and memory cost of per-parameter
AllGather, the Gradient Buffer ofDDPis reused as the communication buffer forAllGather.
- Overlap the parameter
AllGatherwith the forward computation in the next iteration for hiding communication overhead, similar to gradientReduceScateroverlap with backward computation
How to use it?
APIs can found in: <repo>/vescale/optim/distributed_optimizer.py.
More examples can found in: <repo>/test/parallel/ddp_optim/test_doptimizer.py.
veScaleBasicOptimizer
BasicOptimizer is a not ZeRO optimizer but a simple optimizer that works like Data Parallel which replicates parameters, gradients, and optimizer states along Data Parallel dimension.
BasicOptimizer itself is nothing but a simple wrapper that wraps given optimizer instance with utilities for veScale DTensor, DModule, and DDP:
-
convert between
TensorandDTensor -
recover flattened gradient from
DDP -
trigger gradient synchronization of
DModule(e.g., for Sequence Parallel)
APIs can be found in: <repo>/vescale/optim/base_optimizer.py.
Examples can be found in <repo>/test/parallel/ddp_optim/test_ddp.py.
How are these optimizers related withDDP?
The compatibility of the above optimizers with DDP is as follows:
BasicOptimizer | DistributedOptimizer | |
|---|---|---|
DDP | yes | yes |
NO DDP | yes | no |