DTensor (Distributed Tensor)
TLDR
Why DTensor?
-
torch.Tensorlacks the semantic of being distributed across multiple devices and running distributed operators -
Manually managing
torch.Tensorin distributed settings is painful and error-prone, as it demands the manual handling of the sharded storage on each device, the collective communication among devices, and the operator kernel split across devices, all with great care.
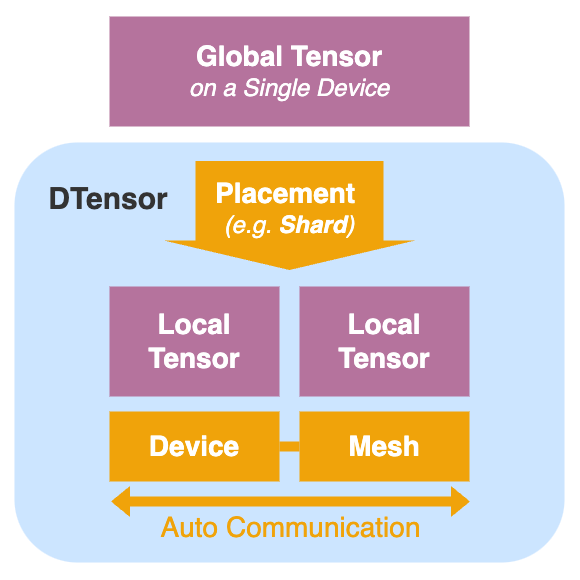
What is DTensor?
-
DTensor (Distributed Tensor)provides a single-device abstraction for multiple-devicetorch.Tensorand empowers user to write distributed training/inference code as if on a single device (i.e., SPMD) -
DTensortransparently handles all distributed logic under the hood (sharded storage on each device, the collective communication among devices, and the operator kernel split across devices) -
DTensoris implemented by a wrapper class ontorch.Tensorwith a meta dataDTensorSpecdescribing:-
which multiple devices (
DeviceMesh) is distributed upon- it can be 1D mesh of two GPUs:
DeviceMesh("cuda", [0, 1]) - it can be 2D mesh of four GPUs:
DeviceMesh("cuda", [[0, 1], [2, 3]])
- it can be 1D mesh of two GPUs:
-
how is
DTensorplaced (Placement) on theDeviceMesh:-
there are three main
Placement:Shard(<tensor_dim>):DTensor's<tensor_dim>is sharded on theDeviceMeshReplicate:DTensoris replicated on theDeviceMeshPartial:DTensoris a partial product on theDeviceMeshwith pending sum (AllReduce) to be a total product
-
where a list of
Placementis needed to define theplacementsof aDTensor:-
placements = [Shard(1)]meansDTensor's tensor dim #1 is sharded alongDeviceMesh's dim #0 (i.e., the #0 element in the list) -
placements = [Shard(1), Shard(0)]meansDTensor's tensor dim #1 is sharded alongDeviceMesh's dim #0 andDTensor's tensor dim #0 is sharded alongDeviceMesh's dim #1 -
placements = [Shard(1), Replicate()]meansDTensor's tensor dim #1 is sharded alongDeviceMesh's dim #0 andDTensor's rest tensor dim #0 is replicated alongDeviceMesh's dim #1
-
-
-
what is the global tensor shape & stride (
TensorMeta) of thisDTensor
-
-
DTensoroperators (e.g.,torch.add) are implemented byShardingPropagatorwhich propagatesplacementsfrom input to output for each operator with pre-registered sharding rules and strategies
What is veScale DTensor? How's different from PyTorch DTensor?
-
veScale is a PyTorch-native framework rooted in PyTorch DTensor
-
veScale DTensor extends and enhances the PyTorch DTensor for our production standard with extra features as below:
-
enabled "correct random ops" under abitrary sharding and uneven sharding, i.e., always guarantee random op sharded on multi device is equal to random op on a single device.
-
enabled DTensor support for third-party plug-in ops (e.g.,
APEX) by unleashingDTensor.data_ptrand handling asynchronous collective tensors (e.g., infrom_local,to_local,redistribute) -
make implicit
_Partialto explicitPartialplacement for optimized initialization, output, and checkpoint (with an extra dispatch mode) -
enabled DTensor ops that were not implemented in PyTorch for forward or/and backward:
argmaxargmintopk_unique2scatter_scatterselectaliasindex_put_index_putindex_add__scaled_dot_product_flash_attention_scaled_dot_product_efficient_attentionexpand_asone_hotwhereEmbeddingin vocabular parallel
-
support uneven sharding in conversion between
DTensorandtorch.Tensor -
decoupled special op handling that bypasses DTensor dispatching (
_bypass_for_dispatch) -
enabled patching before (
_pre_patch_for_dispatch) and after (_post_patch_for_dispatch) DTensor dispatch, for adding user's custom dispatching logic without coupling original dispatch logic -
enabled short-cut for ops to bypass sharding propagation entirely (
_bypass_for_sharding_prop): -
bypassed
tensor_metapropagation for ops:- with output DTensor as pure
Replicate, by using local output Tensor'stensor_meta - with registered
tensor_metapropagation underdtensor/ops(e.g.,conv,slice,copy,clone,bucketize,t) - excluding ops in
recompute_tensor_meta_list(e.g.,clone,native_dropout,nll_loss_forward)
- with output DTensor as pure
-
enabled
DeviceMeshonmetadevice type -
enabled
DeviceMeshinitialization from an existing processs group -
enabled
DeviceMeshbeing split into a list of sub meshes -
disabled redistributed input:
- torch DTensor allows each op select its best sharding strategy for input-output sharding based on a cost model capturing input redistribution communication and then redistributes input DTensor to selected input-sharding.
- But we currently disable this feature (via environment var
VESCALE_DISABLE_REDISTRIBUTE), as we don't expect uncontrollable resharding and implicit communication in DTensor dispatch for production. (Ideally, all resharding and communication should be controlled by the end users.)
-
support deferred initiailization and materialization for DTensor with extended
torchdistx -
[experimental] developed
InterleavedShardplacement to support merged QKV in MHA -
[experimental] extreme performance with C++ DTensor
-
[experimental] extreme performance with dispatching-free DTensor
-
How to use veScale DTensor manually?
-
Example of
matmul: -
APIs can be found under
<repo>/vescale/dtensor/api.py -
More examples can be found under
<repo>/test/dtensor/*/*.py -
Original examples can be found in PyTorch DTensor.
What if encountering an operator that is not supported by DTensor yet?
-- Register DTensor "Ops" for Sharding Propagation!
Why register DTensor Ops for sharding propagation?
Sharding propagation is an important step in DTensor dispatch. It is responsible for inferring the output sharding info (i.e., DTensorSpec) from the input sharding info at each operator. So that the all ops of an entire model can be expressed in DTensor.
How to register a DTensor Op for sharding propagation?
There are two ways to register sharding propagation, namely:
- rule-based way (deprecated by upstream, will be converted to strategy-based for all ops in future)
- strategy-based way
They're the same thing intrinsically. But the difference between the rule-based and strategy-based way is that the former only needs to consider the current input DTensorSpec while the later requires enumerating all valid (input DTensorSpec, output DTensorSpec) pair for a single op.
The pros of the rule-based way is the ease of use, while pros of the strategy-based way is having all possible combinations of input-output sharding -- a context info necessary for automatically selecting the best strategy for input-output sharding (e.g., the one with the minimal DTensor redistribution cost).
It's recommended to use strategy-based way to register sharding propagation. But if you encounter a really complex custom op, rule-based way might be the better choice.
Example of the rule-based sharding propagation registration
Example of the strategy-based sharding propagation registration
How to generate random numbers in DTensor as if it's from a single GPU?
Motivation
Ideally, DTensor should provide single-device abstraction even for random ops (e.g. dtensor.randn, nn.Dropout, and <any random ops>), i.e., random value generated on single device should be identical to collective of random shard on multiple devices.
Problem
PyTorch DTensor (i.e., OffsetBasedRNGTracker) does not produce the random values on multiple devices identical to single GPU execution for random operators (e.g. dtensor.randn, nn.Dropout, and <any random ops>).
The key problem lies in that the CUDA random numbers are not generated "sequentially" and cannot be simply offsetted by rank ids, but instead are generated "simultaneously" by multiple CUDA threads and only be sharded by CUDA thread ids!
Solution
In veScale, we introduce a ThreadBasedRNGTracker for correcting the RNG states across different GPUs, enabling generation of correct DTensor that are identical to the ones from single GPUs for any random ops.
To use the feature, build and install a patched PyTorch of veScale and set the environment variable VESCALE_SINGLE_DEVICE_RAND=1.
Details
Whenever invoking a randomized operation on a DTensor, ThreadBasedRNGTracker passes its sharding info to the C++/Cuda side of PyTorch through the RNG state.
This resolves the issue that PyTorch DTensor's OffsetBasedRNGTracker does not produce the output identical to single GPU executions.
For example, consider generating x = torch.rand(4) given the current random seed and
a global offset. In Cuda's RNG implementation, random numbers are accessed via a triple
(seed, thread id, offset).
On a single GPU, 4 GPU threads is created and the i-th thread fills the entry x[i]
with rand(seed, i, offset). That is, we have
After the execution of torch.rand(4), the global offset increments by 4, which is the
granularity of cuda's RNG offsets.
The global offset increments by the size of the randomness used in each thread, rounded up to the nearest multiple of 4. For instance, if 1000 GPU threads is used to generate 7000 random numbers, each thread takes 7 random numbers from Cuda RNG and the global offset increases by 8 afterward.
However, using OffsetBasedRNGTracker, it outputs a different tensor given 2 GPUs.
Furthermore, after the execution, the global offset increments by 8 instead of 4.
To resolve the issue, each physical thread of each GPU should fill the entry using the thread id as if there is only one GPU. In the previous example, the output should be
And after the execution, the global offset should increment by 4. This can be done if we pass the sharding info into Cuda functions that generate these outputs.
Acknowledgement
We would like to acknowledge the assistance of and collaboration with the PyTorch DTensor team.