veScale DModule for Tensor Parallel & Sequence Parallel
TLDR
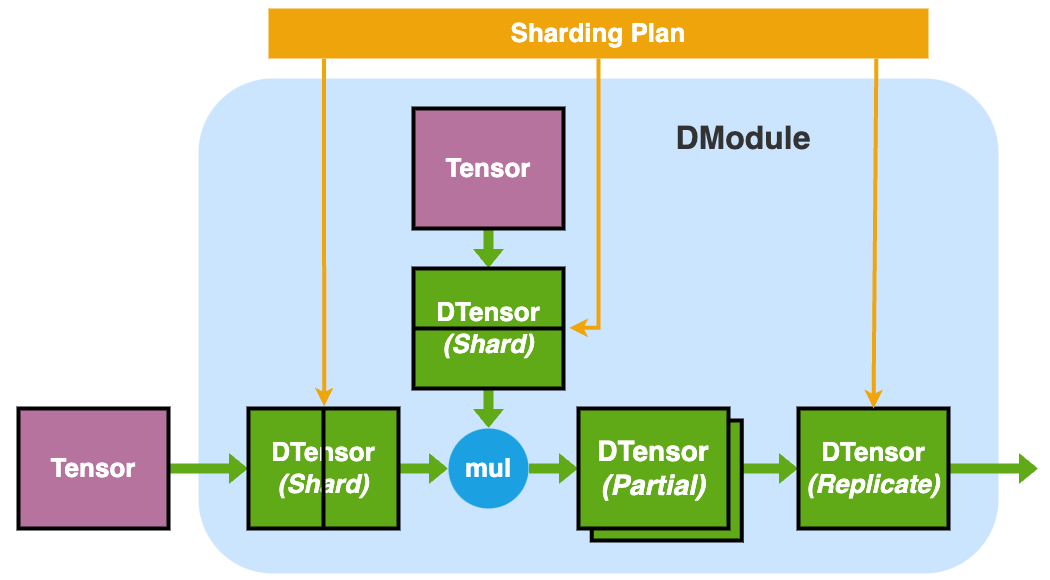
Why veScale DModule?
-
nn.Modulelacks the semantic of being distributed across multiple devices and running distributed operators -
Manually managing
DTensorandTensorwithin ann.Modulein distributed settings is painful and error-prone.
What is veScale DModule?
-
DModule (Distributed Module)provides a single-device abstraction for multiple-devicenn.Moduleand empowers user to write distributed training/inference code as if on a single device (i.e., SPMD) -
DModuleunifies Module-level Tensor Parallelism and Sequence Parallelism by transparently handling distributed logic under the hood:- convert
TensortoDTensorwithin ann.Module - manage
DTensorsharding and resharding during forward and backward - configure (re)sharding of
DTensorvia Module-level APIparallelize_module()with givensharding_plan - allow
sharding_planto be either:- imported from a pre-defined "plan zoo"
- given by "manually written" json
- [experimental] given by "automatical plan generation" of veScale
- handles gradient synchronization automatically in backward
- support deferred initialization with
deferred_init()(i.e., initialize withFakeTensor without allocating memory, then shard Fake Tensor with TP, and then materialize only a shard ofTensoron device) - support third-party plug-in Module (e.g.
APEX) - provide patch interface for customized Module-level hacking
- extend to optional DP, optional FSDP, and optional EP (in the future)
- provide debuggability for easy dumping, printing, listing, etc.
- convert
Difference of veScale DModule from PyTorchparallelize_module?
-
veScale
DModuleis inspired by PyTorch'sparallelize_module, but is developed with explicit Module-level abstraction with complete features for our production usage. -
veScale
DModuleextends PyTorchparallelize_modulewith extra features as below:- nD Tensor Parallelism
- Sequence Parallelism
- auto gradient synchronization
- deferred initialization
- third-party plug-in Module
- module-level patch interface
- [experimental] automatical plan generation
How to use veScale DModule manually?
-
Example of
MLP: -
APIs can be found in
<repo>/vescale/dmodule/api.py -
More examples can be found under
<repo>/test/dmodule/*.py